My Journey Setting Up an Avalanche Validator - The Stability Puzzle
Recently, I took on a challenge: deploy, monitor, and operate an Avalanche Fuji Testnet validator node. With a solid DevOps background, my go-to strategy was clear: automate with Ansible and Docker for what seemed like a straightforward task. I anticipated a quick setup and then focusing on the monitoring aspects. However, the path from deployment to stable operation proved much more winding and educational.
The Initial Plan & Early Success: Automation First
True to DevOps principles, I started with Ansible for server setup and configuration, templating the necessary files (docker-compose.yml, node_config.json). Docker was the natural choice for the avalanchego node, promising consistency and easy management. The initial deployment went smoothly. After navigating the usual small hurdles – finding the right testnet faucet (using Core Wallet + discount codes like avalanche-academy) and understanding the P-Chain/C-Chain mechanics for registration (including retrieving NodeID and BLS keys from logs) – the Dockerized node came online, synced up, and was successfully registered as a validator. On day one, everything looked green.
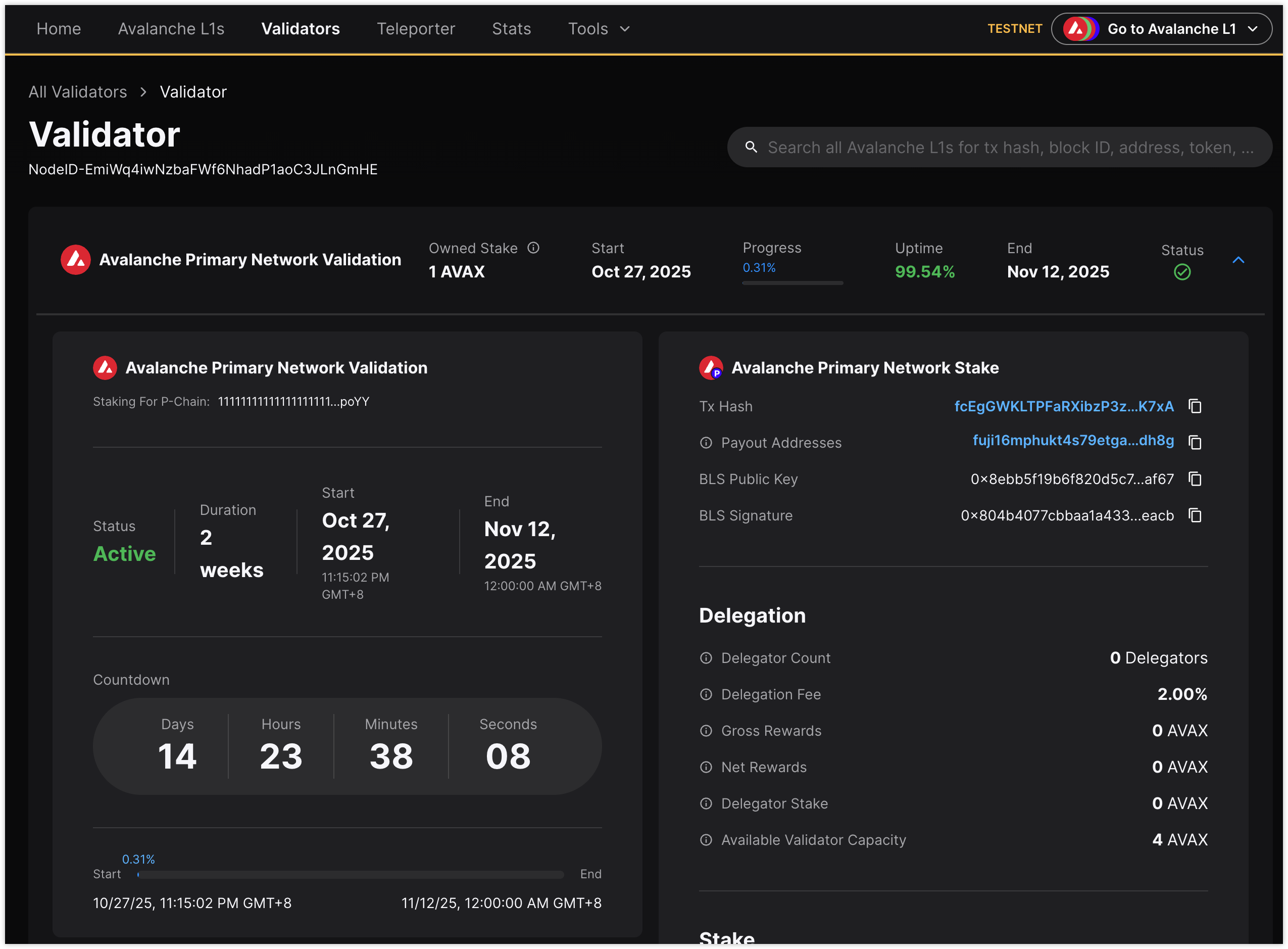
The real test began on day two. I woke up to find the validator, which seemed perfectly healthy the day before, showing as accessible=no and online=no on the Fuji Explorer, eventually leading to benched=yes.
This kicked off an intense troubleshooting session, characterized by a frustrating discrepancy:
Internal Checks: All Systems Go: Running checks inside the EC2 instance painted a picture of health. The
health.healthAPI reportedhealthy=true(once past the initial subnet sync). System resources (htop,iostat) showed CPU, memory, and disk were practically idle. The node was advertising the correct public IP (info.ip). System time (timedatectl,chrony) was perfectly synchronized.External Perception: Offline: Despite all internal indicators being positive, the external view from the Avalanche network (via the Explorer) insisted the node was unreachable.
I systematically worked through potential causes:
Firewall: Double- and triple-checked AWS Security Groups and confirmed port
9651was open externally usingnclistening internally and external port checkers.ufwwas inactive.IP Address: Confirmed the node was advertising the correct, unchanged public IP.
Clock Sync: Verified
chronywas active and synchronized.Resources: Confirmed CPU, Memory, and Disk I/O were far from exhausted.
Log Analysis: Dug through docker logs for network, consensus, or handshake errors.
Docker Networking: Inspected
iptables, restarted the Docker daemon and the container multiple times, and even briefly testednetwork_mode: host– none resolved theaccessible=nostatus.Node State: Tried forcing a peer list refresh by removing
peers.json.
Despite trying every standard troubleshooting technique, the root cause for the Dockerized node’s inaccessibility remained elusive. It could talk out, but the network couldn’t reliably talk in at the protocol level, even with the port open.
Shifting Strategy: The Official Installer Script
After hitting a wall with the Docker setup, I decided to eliminate it as a variable. I pivoted to using the official Avalanche installer script, as recommended in the documentation. This wasn’t just placing a binary; the script handles downloading the correct version, setting up the systemd service, creating necessary users/directories, and configuring basic parameters. Understanding the script and its arguments was key here.
Interestingly, even after a successful deployment using the official script, the same phenomenon occurred initially: the node synced, internal health checks eventually looked okay, but the Explorer stubbornly reported accessible=no.
The Last Resort: A Full Reboot
Having exhausted specific troubleshooting steps on both Docker and native setups, with all signs pointing to a subtle, persistent network communication issue despite configuration appearing correct, I took the final step: a full server reboot (sudo reboot).
After the instance came back up and the systemd service automatically restarted the native avalanchego node, I waited for it to sync again. This time, the node started reporting as accessible=yes and online=yes on the Explorer. While I’m cautiously optimistic it will remain stable, it highlights how elusive some P2P network issues can be.
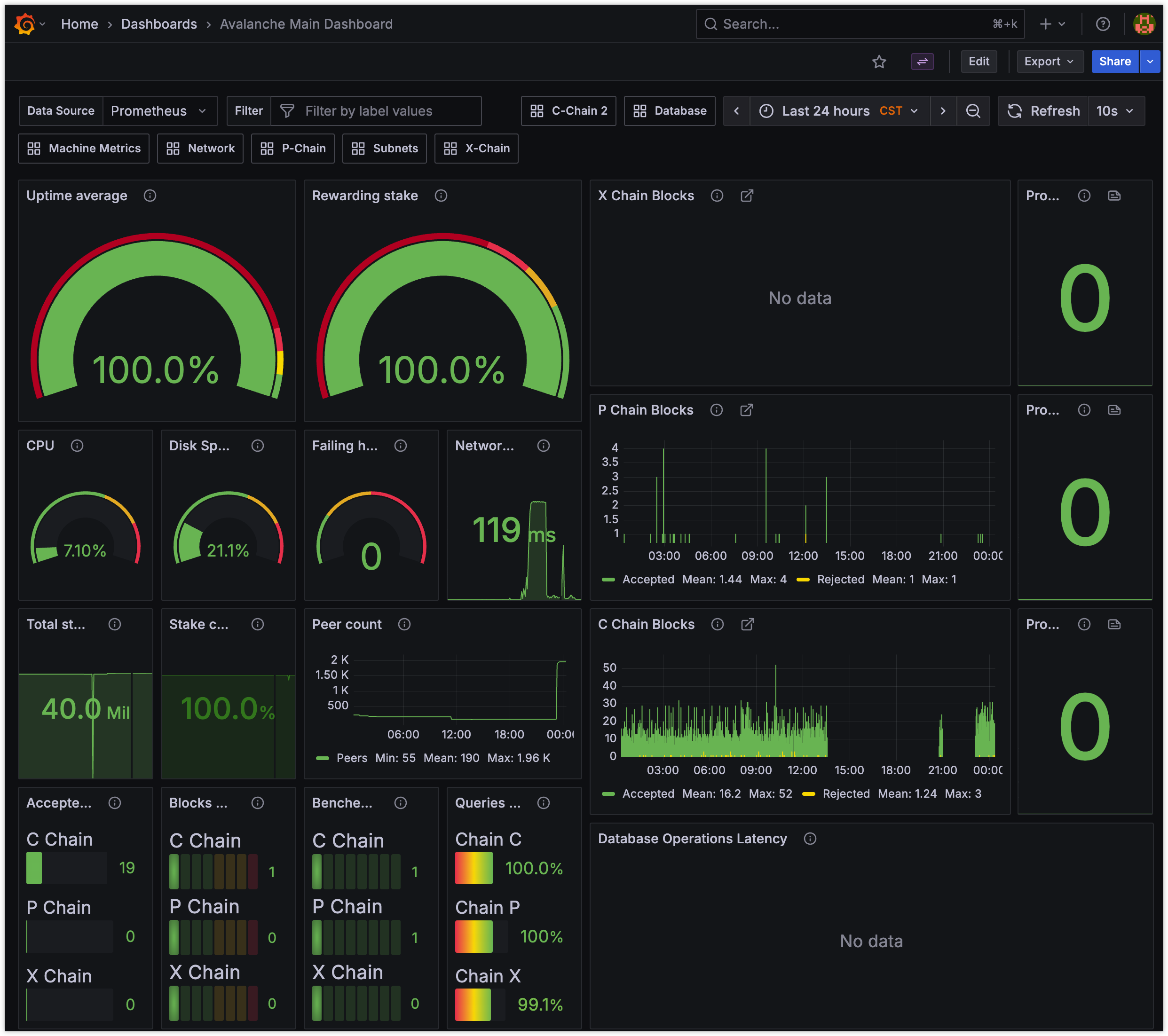
Key Takeaways: Automation, Docs, Monitoring
This experience, while challenging, was incredibly valuable:
Automation is the King: Even though I ended up with a native deployment, having Ansible scripts ready made iterating through setups (Docker, native, configuration changes, monitoring stack) vastly more efficient. Manual repetition would have been painful. IaC is crucial for managing complexity and ensuring repeatability.
Official Docs & Scripts are Foundational: The official installer script provided a reliable baseline for the native deployment. While not a magic bullet (as the issue persisted initially), it eliminated many potential setup errors. Always start with the official source.
Internal Health != External Accessibility: This was the core lesson. A node can appear perfectly healthy from its own perspective (API checks, resource usage) but still fail to communicate effectively with the P2P network. Diagnosing this requires looking beyond internal metrics.
Monitoring: Leverage Official Resources: Deploying Prometheus/Grafana confirmed the value of monitoring, but also showed the efficiency of using the official Grafana dashboard. It’s pre-configured for key metrics and implicitly guides you towards best practices (like needing
node_exporterfor host stats). Don’t reinvent the wheel unless necessary.Web3 is Nuanced: The challenge provided practical exposure to L1 concepts, Avalanche’s specific P/C/X chain architecture, Subnets, and the critical details of staking and network health – things you only truly grasp through hands-on experience.
Sometimes, You Reboot: While not intellectually satisfying, sometimes a full system reboot can clear deep-seated, transient issues in the OS networking stack or service interactions that are difficult to pinpoint otherwise.
Conclusion
Deploying an Avalanche validator turned out to be less about the initial setup and more about diagnosing subtle operational stability issues. The discrepancy between internal health checks and external network accessibility was a significant hurdle. The troubleshooting journey, though frustrating at times, deepened my understanding of node operations, networking, and the importance of robust automation and monitoring.
All commands, scripts, notes, and the final Ansible playbooks used during this challenge are documented in my GitHub repository:
Thanks for the challenge! It was genuinely fun and insightful.